
Of late, there has been quite a lot of interest in increasing/improving the context of LLMs. One good example is the
There are mainly two contributions from the paper:
-
A data-driven approach that introduces a novel pipeline to synthesize a novel dataset to train LLMs to cleverly use long contexts. It’s dubbed “Information-Intensive Training” (IN2 in short).
-
A novel evaluation approach named Various Long-Context (VAL Probing) uses 3 context styles — document, code, and structured data and 3 retrieval patterns — forward, backward, and bi-directional.
In this article, let's deep-dive into both the simple ideas followed by some evaluations.
Visual Explanation
If you are someone who likes audio-visual explanations, here is a video version of this article that explains the paper:
https://youtu.be/SA21d_4QQSU?feature=shared&embedable=true
IN2 Training
The first main idea of the paper is a novel data-driven training approach named IN2 training. There are two types of IN2 training proposed in the paper.
- Fine-grained Information Awareness. In this case, we first take a raw text dataset and split it into 128 tokens and we call each of this set of 128 tokens a “segment.” We then prompt a powerful LLM model like GPT-4 with an instruction I_f in such a way that the answer a_i to this question q_i requires information in the segment s_i to provide the answer. We then combine the segment s_i with several other segments by shuffling it along with the other segments to create the long context L_i.
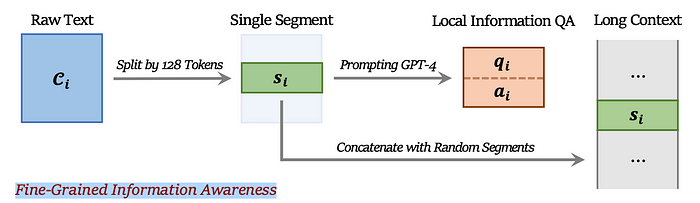
Figure taken from the paper (figure 2).
- Integration and Reasoning of Information. There can be situations where the context is located in more than one segment (more than 128 tokens). So we consider a set [s_i] instead of a single s_i. This creates a multi-hop Q&A scenario where the LLM has to do at least 2 passes of QAs. We modify the instruction I_f in the prompt to the LLM accordingly.
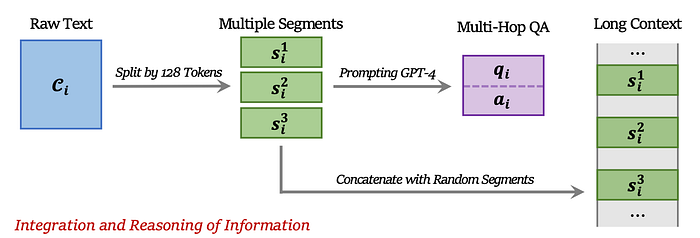
Figure taken from the paper (figure 2)
In both scenarios, the authors vary the long context length L_i from 4K to 32K to prevent length bias in training. During IN2 instruction fine-tuning, the long contexts and questions become input to the LLM, and the answer is shown as the output for supervised training. They fine-tune the Mistral-7B-Instruct-v2 model and call the new model FILl-in-the-Middle(FILM-7B).
VAL Probing
VArious Long-context Probing or VAL Probing was introduced to overcome some of the problems with the current LLMs with retrieving from long contexts. So how do we even test the long context retrieval capability of any given model? The answer lies with “Needle in a haystack” (NIHS) test. It can be accessed
Needle in a Haystack
NIHS was proposed to pressure test LLMs. It’s a simple analysis to test the in-context retrieval ability of long-context LLMs. The test can be run by following the below 3 steps:
-
Place a random fact or statement (the ‘needle’) in the middle of a long context window (the ‘haystack’).
-
Ask the model to retrieve this statement.
-
Iterate over various document depths (where the needle is placed) and context lengths to measure performance.
The biggest problem with NIHS these days is that the recent models perform too well making the test less appealing. For example, see below the test result of the proposed FILM-7b model
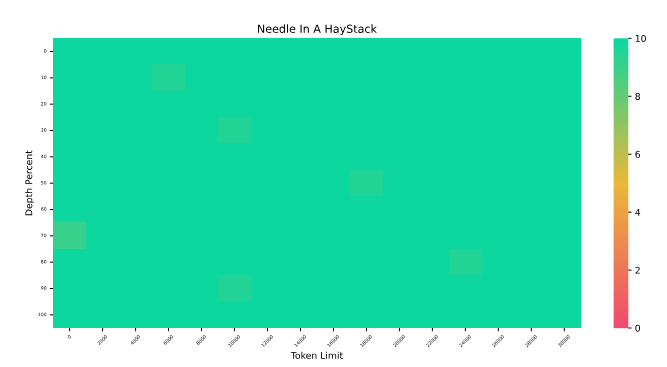
NIHS test on the proposed FILM-7b model
The results are near perfect indicating that we really need a new testing approach and so, giving birth to VAL Probing.
VAL Probing
VAL probing considers 3 data types such as documents, structured data, and code. It also considers three retrieval types — forward, backward, and bi-directional. The below figure from the paper gives examples of all three data types and retrieval directions.

Results
For evaluation, they used the LongBench evaluation scripts and reported ROGUE-L for summarization and F1-scores for all other tasks.
The first problem addressed by the paper is the “Lost-in-the-middle” problem. As shown in the below figure, we can see that there is no “U” shaped dip with the FILM-7b model (in orange) compared to Mistral-7B (green), and even other long-context sota models like LongAlign indicating the strength of FILM-7b.
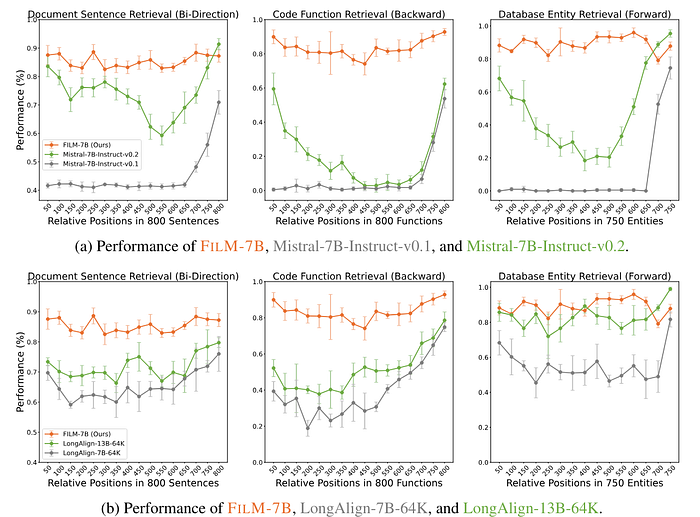
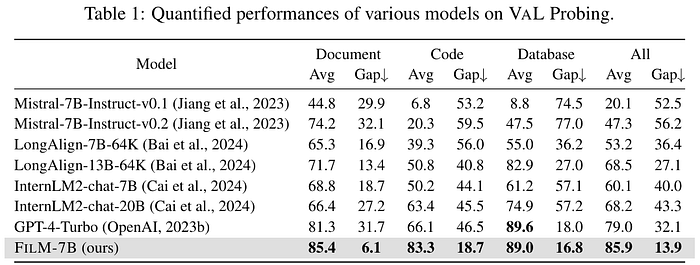
On top of addressing the Lost-in-the-middle problem, FILM-7B seems to outperform other recent models quantitatively too. They show the results of averaging the evaluation metric(Avg) and min-max gap of the evaluation metric (Gap) which is the difference between the minimum and maximum values obtained. In short, the model is comparable to GPT-4’s performance!
Summary & Conclusion
This paper from Microsoft proposes a simple data-driven solution to addressing the long-context problem in LLMs. On top of proposing a data generation pipeline, it also proposes and tests the usage of the novel VAL Probing that encompasses 3 data types and 3 retrieval methods.
Let’s hope this is just the dawn of a new generation of LLMs that are no longer limited by the context length.
See you in my next…