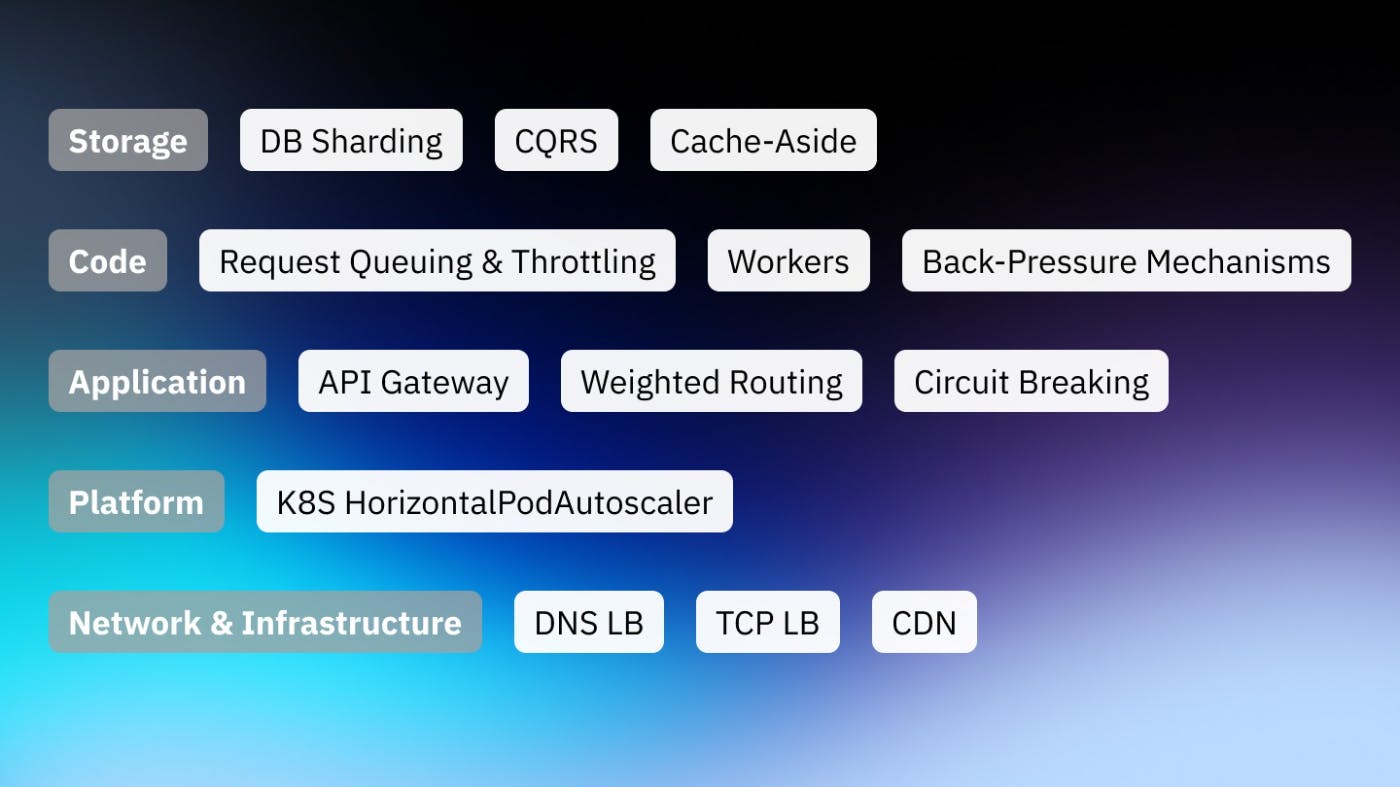
The smooth functioning of an application largely depends on how well it manages loads. You may have just one application instance with limited resources and a huge workload to balance. You may have a cluster of application replicas or a multi-server setup and the need to efficiently distribute network traffic and workload, ensuring that no single server bears too much demand.
Load balancing not only prevents servers from becoming overwhelmed but also improves responsiveness and increases availability, providing a seamless experience for users. In this guide, we'll explore different load-balancing strategies across various layers of an application, from infrastructure to the database, up to the application code.
Load Balancing at the Network & Infrastructure Level
Infrastructure forms the backbone of any application, and efficient load balancing at this level can significantly impact the application's performance and scalability.
DNS Load Balancing
DNS (Domain Name System) Load Balancing is one of the earliest and simplest forms of load balancing. In essence, it operates at the infrastructure level and translates domain names into IP addresses.
The DNS server can return different IP addresses in a round-robin manner for each query it receives. In the context of microservices, each microservice could have multiple instances running on different servers, each with its unique IP address. DNS Load Balancing could return the IP address of a different server instance for every new request, ensuring that requests are distributed across all the available instances.
A few of the critical benefits of DNS LB:
- Geographic Distribution: DNS load balancing can direct traffic to the nearest application instance geographically, minimizing latency and improving overall performance.
- Failover Handling: DNS Load Balancing can also help with failover. If a server fails, the DNS can stop directing traffic to that server's IP address and redistribute it among the remaining servers.
- Scalability: As the system scales and more instances of an application are added, DNS Load Balancing automatically includes them in the pool of resources for traffic distribution.
However, it's crucial to consider the limitations of DNS Load Balancing in a microservices environment:
-
Caching Issues: DNS responses can be cached at various places (like local machines or intermediate ISP servers), meaning a client might continue to send requests to a server that is down.
-
Lack of Load Awareness: DNS load balancing isn’t aware of the server’s load or capacity; it only rotates through the IP addresses in a round-robin manner.
-
Inconsistency in Session Persistence: If your application requires a client to stick to the same server for a session, DNS load balancing might not be the best choice as it doesn't inherently support session persistence.
In conclusion, while DNS Load Balancing offers simplicity and cost-effectiveness, it's a fairly rudimentary form of load balancing. Depending on the complexity and requirements of your application architecture, you may need to complement it with other load-balancing strategies or opt for a more sophisticated solution like a Load Balancer or a Service Mesh.
Transport Level / TCP Load Balancing
TCP (Transmission Control Protocol) load balancing operates at the transport layer (Layer 4) of the OSI networking model. It distributes client requests based on TCP sessions rather than individual IP packets, making it more efficient and reliable than other types of load balancing.
Here's how TCP Load Balancing can help manage workloads in a microservices environment:
- Persistence: TCP load balancers track the state of TCP connections. They can ensure that all session packets between a client and a server are sent to the same server, even if more than one server is associated with the destination IP address.
- Efficiency: Because TCP load balancing operates at the transport layer, it can handle traffic at a high rate and with low latency. This can significantly enhance the efficiency of services that process large amounts of data or require real-time communication.
- Health Checks: TCP load balancers can periodically check the health of the backend servers and stop sending traffic to any server that fails these checks. This ensures high availability and reliability for your services.
- Scalability: TCP Load Balancing allows easy horizontal scaling of your services. As you add more instances of a service, the load balancer can automatically distribute traffic to these new instances.
However, TCP Load Balancing also has some limitations in a microservices context:
-
Lack of Application Context: As TCP load balancing operates at the transport layer, it doesn't have any knowledge of the HTTP requests and responses. This means it can't make decisions based on the content of the HTTP messages.
-
Session Drift: If a server goes down and comes back up, the sessions that were tied to it may drift to other servers, leading to an uneven distribution of load.
Despite these limitations, TCP load balancing is a powerful tool that can enhance the performance and reliability of your microservices. It's particularly beneficial for applications that process a high volume of traffic, require session persistence, or need to handle large amounts of data. For more complex needs, application-level load balancing or using a service mesh might be more suitable.
CDN
A Content Delivery Network (CDN) is another powerful tool to balance load by serving static content to users from the nearest geographical point of presence (PoP), reducing latency and offloading the origin server.
Load Balancing at the Platform Level
At the platform level, we delve deeper into specific software or platform-level load balancing strategies.
In a Kubernetes environment, load balancing can be done at two levels - internally among the pods and externally for the client-to-service access. Services inside Kubernetes can automatically distribute requests among the right pods using cluster IP, while Ingress controllers or cloud provider load balancers can handle external traffic.
Here's a simple, conceptual example using Kubernetes, a platform that supports horizontal scaling. Suppose you have a Kubernetes Deployment for your API service:
apiVersion: apps/v1
kind: Deployment
metadata:
name: my-api
spec:
replicas: 3
selector:
matchLabels:
app: my-api
template:
metadata:
labels:
app: my-api
spec:
containers:
- name: my-api
image: my-api:1.0.0
You can automatically scale this Deployment based on CPU usage with a Kubernetes HorizontalPodAutoscaler:
apiVersion: autoscaling/v1
kind: HorizontalPodAutoscaler
metadata:
name: my-api
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: my-api
minReplicas: 3
maxReplicas: 10
targetCPUUtilizationPercentage: 80
This example will scale the number of pods running your API between 3 and 10, attempting to maintain an average CPU usage across all Pods of 80%.
Load Balancing at the Application Architecture Level
At the application architecture level, load balancing is achieved by strategically distributing responsibilities among different services or components.
Microservices
Microservices architecture is a design pattern in which an application is broken down into smaller, loosely coupled services. Each microservice is responsible for a specific functionality and can be developed, deployed, and scaled independently.
For instance, in a typical e-commerce platform, different functionalities like user authentication, inventory management, payment processing, and order management can be broken down into individual microservices. Each of these microservices can then be independently scaled based on its own traffic patterns.
API Gateway
API Gateway serves as a single-entry point for clients, making it an ideal spot for load balancing. It can route requests to different services based on predefined rules, effectively distributing workload. This pattern can help not only with load balancing, but also with complexity balancing, leading to:
- Separation of concerns — Frontend requirements will be separated from the backend concerns. This is easier for maintenance.
- Easier to maintain and modify APIs — The client application will know less about your APIs’ structure, which will make it more resilient to changes in those APIs.
- Better security — Certain sensitive information can be hidden, and unnecessary data to the frontend can be omitted when sending back a response to the frontend. The abstraction will make it harder for attackers to target the application.
Service Meshes
In the context of Service Meshes, sidecar proxies like Envoy can be used to apply fine-grained control over the network communication between services. It is a dedicated infrastructure layer built right into an app. This visible infrastructure layer can document how well (or not) different parts of an app interact, so developers can optimize communication and avoid downtime.
In the context of load balancing, service meshes offer sophisticated traffic management capabilities. They allow you to manage and control the traffic flowing between your services, enabling advanced load balancing strategies like weighted routing, request shadowing, and circuit breaking.
Service meshes such as Istio, Linkerd, or Consul offer a rich set of features that enhance the security, observability, and traffic control of microservices.
Let's take Istio as an example:
Weighted Routing: This is useful when you're gradually rolling out a new version of a service. You can route a small percentage of traffic to the new version, observe its behavior, and then increase the percentage if everything is functioning as expected. Here is an example configuration in Istio:
apiVersion: networking.istio.io/v1alpha3
kind: VirtualService
metadata:
name: my-service
spec:
hosts:
- my-service
http:
- route:
- destination:
host: my-service
subset: v1
weight: 90
- destination:
host: my-service
subset: v2
weight: 10
In this example, 90% of the traffic is routed to version 1 of the service and 10% to version 2.
Circuit Breaking: This is a design pattern used in modern software development to improve the resilience of your system. In a distributed system, services constantly call each other. If a called microservice is failing or responding slowly, it may affect other services. Circuit breaking can be used to avoid this problem. For example, Istio can be configured to stop sending requests to a service if it fails a certain number of times:
apiVersion: networking.istio.io/v1alpha3
kind: DestinationRule
metadata:
name: my-service
spec:
host: my-service
trafficPolicy:
connectionPool:
tcp:
maxConnections: 1
http:
http1MaxPendingRequests: 1
maxRequestsPerConnection: 1
outlierDetection:
consecutiveErrors: 1
interval: 1s
baseEjectionTime: 3m
maxEjectionPercent: 100
In this example, if a service fails even once (consecutiveErrors: 1), it will be ejected from the load balancing pool for 3 minutes (baseEjectionTime: 3m).
Service meshes are particularly helpful in a microservices architecture because they enable you to manage inter-service communication in a distributed and scalable way. They provide fine-grained control over how traffic is routed between your services, allowing you to optimize load balancing according to your specific requirements.
Load Balancing at the Application Code Level
Load balancing can also be introduced programmatically, within the application's codebase itself.
Client-Side Load Balancing involves the client choosing which server to send requests to. While this gives clients more control, it requires them to be aware of the available servers and their load.
Utilizing Libraries and Frameworks that support distributed processing can help evenly distribute load across worker nodes. Examples include RabbitMQ, Apache Kafka, or even language-specific libraries like Python's Celery.
Request Queuing
Request queuing is a strategy where incoming requests are temporarily held in a queue until they can be processed. This approach allows you to manage high volumes of incoming requests without overloading the system.
Here's a simple TypeScript example using an array as a queue:
// Create a queue
let queue: string[] = [];
// Add requests to the queue
queue.push('request1');
queue.push('request2');
// Remove a request from the queue for processing
let request = queue.shift();
// Process the request
console.log(`Processing: ${request}`);
Request Throttling
From the other side, you can smooth out the outcome workload by throttling requests. For example, execute maximum N requests in parallel. You can use libraries like promise-parallel-throttle as a reference.
In the example below, we’re trying to bread the massive list of product updates into batches first, and then executing those batches with a limit of max 5 requests in parallel.
import * as Throttle from 'promise-parallel-throttle';
export const updateProducts = async (
products: Product[],
) => {
// Cut the large array into slices by 20 products
// then execute update requests, but max 5 in parallel
const requestPromises = sliceArray( products, 20 ).map(( productSlice ) => {
return () => updateProductsRequest( productSlice )
})
await Throttle.all( requestPromises, { maxInProgress: 5 } )
}
Worker Processes
The worker processes strategy involves distributing the processing of requests across multiple threads or processes. In Node.js, for example, you can use the cluster module or worker_threads module to create worker processes.
In this example, the master process forks a worker process for each CPU core. Each worker process would then independently process requests, effectively sharing the load.
import cluster from 'cluster'
import os from 'os'
// Fork workers
if (cluster.isMaster) {
const numCPUs = os.cpus().length
for (let i = 0; i < numCPUs; i++) {
cluster.fork()
}
cluster.on('exit', (worker, code, signal) => {
console.log(`Worker ${worker.process.pid} died`)
});
} else {
// This is where worker processes would handle requests
// For example, they could process requests from the queue
console.log(`Worker ${process.pid} started`)
}
Back-Pressure Mechanisms
Back-pressure mechanisms are used to control the rate of incoming requests. If the rate of incoming requests exceeds the rate at which they can be processed, the back-pressure mechanism can signal to the requester to slow down. Here's an example with a simple rate limiter:
class RateLimiter {
private requests: number = 0;
private lastReset: number = Date.now();
// Increase the request count
increment() {
this.requests += 1;
}
// Check if the rate limit has been exceeded
checkRateLimit() {
const now = Date.now();
// Reset the request count every minute
if (now - this.lastReset > 60000) {
this.requests = 0;
this.lastReset = now;
}
// If more than 1000 requests have been made in the last minute, return true
return this.requests > 1000;
}
}
const rateLimiter = new RateLimiter();
// For each incoming request
for (let i = 0; i < 2000; i++) {
rateLimiter.increment();
if (rateLimiter.checkRateLimit()) {
console.log('Rate limit exceeded');
// In a real scenario, you would send a response back to the client to slow down
break;
} else {
// Process the request
}
}
In this example, we're limiting the rate to 1000 requests per minute. If the limit is exceeded, we output a message stating that the rate limit has been exceeded. In a real scenario, you would likely respond to the client with an HTTP 429 status code and a Retry-After header indicating when they should attempt their request again.
Load Balancing at the Database Level
Last but not least, databases can also benefit from load-balancing strategies to handle high volumes of read and write operations.
Database Sharding
Database sharding is a type of database partitioning that separates large databases into smaller, more manageable parts called 'shards'. Each shard is held on a separate database server instance to spread the load. Shards are typically distributed across multiple machines located in different physical locations.
Benefits may be significant for a large-scale application:
1. Performance: As data is distributed across several machines, read/write operations can be executed simultaneously.
2. Increased Availability and Redundancy: If data is correctly distributed, a failure in one shard doesn't affect the availability of the others.
3. Scalability: Sharding allows for horizontal scaling (adding more machines to the network to manage increased load). As your application grows, you can add more shards to handle more data.
Nothing comes without challenges. With sharded DB, we have the complexity of managing multiple shards, the difficulty of performing transactions or joins across shards, and the need for a well-thought-out sharding key to avoid uneven data distribution.
Practical Example: E-Commerce Platform
Let's consider an example of an e-commerce platform with millions of users, products, and transactions. The database might become a performance bottleneck as the platform grows, making operations slower.
To solve this, we could shard the database based on user IDs. Each shard could hold the data for a subset of users, including their profile information, order history, cart, etc. For instance, we could have:
- Shard 1: Users with IDs 1 to 1 million
- Shard 2: Users with IDs 1 million to 2 million
- and so on.
This way, when users interact with the platform, their requests would be directed to the relevant shard. This results in faster query execution, as each shard has less data to deal with. Furthermore, more shards can be added as the platform grows, providing excellent scalability.
Overall, database sharding, while complex to manage, can be an excellent strategy for dealing with large databases and ensuring application performance and scalability. Careful planning and choice of a good sharding key are critical for its success.
Read-Write Separation for Load Balancing
Read-Write Separation, also known as CQRS (Command Query Responsibility Segregation), is an architectural pattern in which read and write operations are separated, often onto different servers or clusters. This approach is particularly useful for applications with heavy read and write loads, as it allows each type of operation to be optimized independently.
Pros here have similar effects to the DB Sharding technique - easy Horizontal Scaling and higher Availability. Also, Different database systems are designed to handle read or write operations more efficiently. With Read-Write Separation, you can choose different systems for read and write operations, enhancing overall performance.
And, of course, the cons - maintaining data consistency between read and write servers and handling latency between updating the write server and reflecting the changes in the read server.
Practical Example: Social Media Platform
Consider a social media platform, where users frequently read posts (like scrolling through their news feed) but write operations (like creating a new post) occur less often. The read operations far outnumber the write operations, but the write operations are usually more resource-intensive.
To manage this, the platform could implement Read-Write Separation. Write operations like creating a new post or updating a user's profile could be directed to a dedicated write server. This server could be optimized for handling write operations efficiently and reliably.
At the same time, read operations like displaying a user's news feed or showing a user's profile could be directed to a cluster of read servers. These servers could be optimized for handling large volumes of read operations quickly and could be scaled out to handle high loads.
Cache-Aside Strategy for Load Balancing
Cache-aside, also known as lazy loading, is a common caching pattern where the application is responsible for reading data from the cache and writing data into the cache when there's a cache miss. This simple approach provides fine control over what gets cached and for how long, making it a good fit for many applications.
Here's how a cache-aside strategy can work in managing loads:
- Read Operation: When the application needs to read data, it first tries to retrieve it from the cache. If the data is found (a cache hit), it's returned immediately, reducing database load and latency. If the data isn't found in the cache (a cache miss), the application retrieves it from the database, puts it into the cache for future requests, and then returns it.
- Write Operation: When the application writes data, it writes directly to the database. Additionally, to keep the cache consistent, it should also invalidate any cached version of the data.
- Cache Eviction Policies: Implementing an effective cache eviction policy, like Least Recently Used (LRU) or Least Frequently Used (LFU), ensures that the most valuable data remains in the cache when space is limited.
The cache-aside strategy, however, does require careful management. It's essential to handle cache misses appropriately to avoid flooding the database with requests, and to manage cache invalidation effectively to ensure data consistency.
Practical Example: Online Retailer
Let's consider a busy online retailer. Certain items are more popular and frequently viewed by customers, leading to a high number of database read operations. A cache-aside strategy can help manage this load effectively.
When a customer requests to view an item, the application first checks the cache. If the item is in the cache (a cache hit), it's returned immediately to the customer. If it's not in the cache (a cache miss), the application retrieves the item from the database, stores it in the cache for future requests, and then returns it to the customer.
In case of an update to the item details, the application writes the new data to the database and invalidates the cached item, ensuring that future reads will fetch the updated data.
By using a cache-aside strategy, the retailer can ensure fast response times for frequently viewed items and effectively manage the load on their database.
Conclusion
Selecting the right load balancing strategy can be a game-changer for your application's performance, scalability, and user experience. It's important to remember that these strategies aren't one-size-fits-all. Factors like your application’s needs, existing architecture, traffic patterns, and scalability requirements all play a role in determining the best approach. By understanding the various layers and techniques available, you can design a robust and scalable system that effectively manages load.
Remember, every system has its unique challenges and requirements. As such, the key to success lies not in adopting the most advanced strategy, but in identifying and implementing the ones that best meet your application's needs.
With that, I hope this guide has provided you with valuable insights into the vast world of load balancing. Here's to building more performant and resilient systems!