
This article series consists of two parts. The first part aims to introduce users to the fundamental components of a time series, explaining its constituents. In the second part, we will focus on quickly modeling the time series and generating predictions.
Introduction
Time-series data is a crucial type of data that represents records of values over time. It differs fundamentally from other tabular data sources in that each data point is sequentially dependent on the previous values. Examples include electricity prices, consumption patterns, inflation rates, and stock prices over time.
Tip: In the realm of Machine Learning and Deep Learning, sequential data holds significant importance, especially in time-series analysis, natural language processing, and large language models (LLMs). An apt analogy to consider is that the forthcoming word in a sentence is inherently linked to the preceding word, just as a timestamp's value is dependent on the previous timestamp in time-series data.
Time-Series Analysis Components
Working with time-series data generally involves one of three main applications:
-
Time-Series Analysis: This entails breaking down the series to understand its constituents, establish relationships, and identify influencing factors - a crucial first step before any modeling.
-
Time-Series Forecasting: Forecasting utilizes machine learning and deep learning models to predict future values as accurately as possible based on historical data.
-
Time-Series Classification: Here, entire time-series sequences are classified, such as categorizing electrocardiogram readings as indicating cardiac conditions or healthy states.

This article focuses on time-series analysis and forecasting, which are highly prevalent applications in the industry.
Time-Series Components
A time-series can be decomposed into three fundamental components:
Time-Series = Trend + Seasonality + Residuals
We will illustrate this through an example of hourly energy consumption data in the US from 2004 to 2018. After importing the necessary libraries, we can extract relevant features from the datetime column, such as day, week, month, and year. This temporal information can reveal insights into trends and seasonal patterns.
In this example, you'll need Python 3 installed, preferably with a Jupyter Notebook, and additional libraries installed. Let's start by installing the following libraries:
!pip install -Uqq kaliedo statsmodels plotly pmdarima pandas numpy
The code block above will install all the necessary libraries for you, allowing you to proceed with the rest of the exercise. Now, let's explore the insights offered by this dataset:
#Importing all the necessary libraries
import pandas as pd
import matplotlib.pyplot as plt
import plotly.express as px
import plotly.io as pio
from sklearn.metrics import mean_absolute_error,mean_absolute_percentage_error
import numpy as np
from statsmodels.tsa.seasonal import seasonal_decompose, STL, MSTL
from statsmodels.tsa.stattools import acf, pacf
from statsmodels.graphics.tsaplots import plot_acf, plot_pacf
from sklearn.ensemble import IsolationForest
from sklearn.preprocessing import StandardScaler
from pmdarima.arima import ndiffs, nsdiffs
df = pd.read_csv('AEP_hourly.csv', sep = ',') #Reading the downloaded data
df.columns = ['datetime','elec_cons'] #Changing the column names
df['datetime'] = pd.to_datetime(df['datetime'], errors = 'coerce') # Changing the datetime to explicit datetime
df = df.sort_values(by = 'datetime')
This dataset comprises two columns. The first column records the datetime of electricity usage, while the second column indicates the actual energy consumption in megawatts (MW). The datetime column is crucial as it encapsulates various temporal representations, including week, month, year, and more.
Tip: The granularity of your data impacts the richness of temporal information that can be extracted. For instance, if your data is recorded at an hourly frequency, you can derive insights ranging from hourly to yearly patterns. The finer the granularity, the more temporal values are available for analysis and interpretation.
Next, we leverage our expertise to extract the aforementioned features. These features will allow us to explicitly gather information from dates, aiding us in modeling and understanding our data:
#Here we extract all the features available in the date columns, and utilize this further for analysis
df["weekday_name"] = df['datetime'].dt.day_name()
df["weekday"] = df['datetime'].dt.weekday
df["week"] = df['datetime'].dt.isocalendar().week
df["day"] = df['datetime'].dt.day
df["hour"] = df['datetime'].dt.hour
df["date"] = df['datetime'].dt.date
df["month"] = df['datetime'].dt.month
df["month_name"] = df['datetime'].dt.month_name()
df["year"] = df['datetime'].dt.year
#Here we make the weekday names, and month names explicitly categorical.
df['month_name'] = pd.Categorical(df['month_name'], categories=["January", "February", "March", "April", "May", "June", "July", "August", "September", "October", "November", "December"], ordered = True)
df['weekday_name'] = pd.Categorical(df['weekday_name'], categories=["Monday", "Tuesday", "Wednesday", "Thursday", "Friday", "Saturday", "Sunday"], ordered = True)
df.head()
Tip: In many machine learning problems unrelated to time-series analysis, shuffling the dataset is common practice to ensure the model learns a balanced representation of the data. However, this is not suitable for time-series data. It's crucial to avoid shuffling time-series data as the temporal order holds valuable information, and shuffling would disrupt this sequential nature.
The initial step is to visualize our data to uncover the underlying relationships with previous time values and identify general trend lines and seasonal patterns.
Visualization
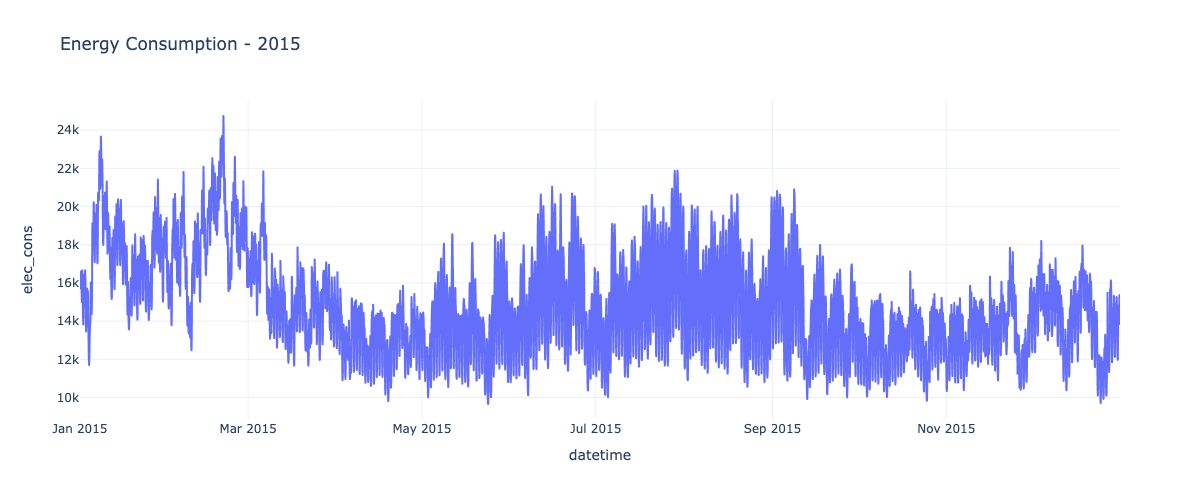
Visualization is a powerful tool for exploring time-series data. By plotting the raw values over time, we can observe overall trends, recurring seasonal patterns, and unusual behaviors. Additionally, plotting rolling averages can help smooth out noise and highlight lower-frequency patterns.
Visualizing subsets of the data, such as specific years or aggregating by time periods like month or hour-of-week, can reveal interesting seasonal patterns. For example, monthly energy consumption may peak during summer for cooling needs or winter for heating. Similarly, hourly patterns may emerge based on residential, commercial, and industrial usage over the course of a day or week.
df_2015 = df[df['year'].isin([2015])].reset_index()
fig = px.line(df_2015,x = 'datetime' ,y = 'elec_cons', title = 'Energy Consumption - 2015')
fig.update_layout(
autosize=False,
width=1200,
height=500,
)
fig.show()
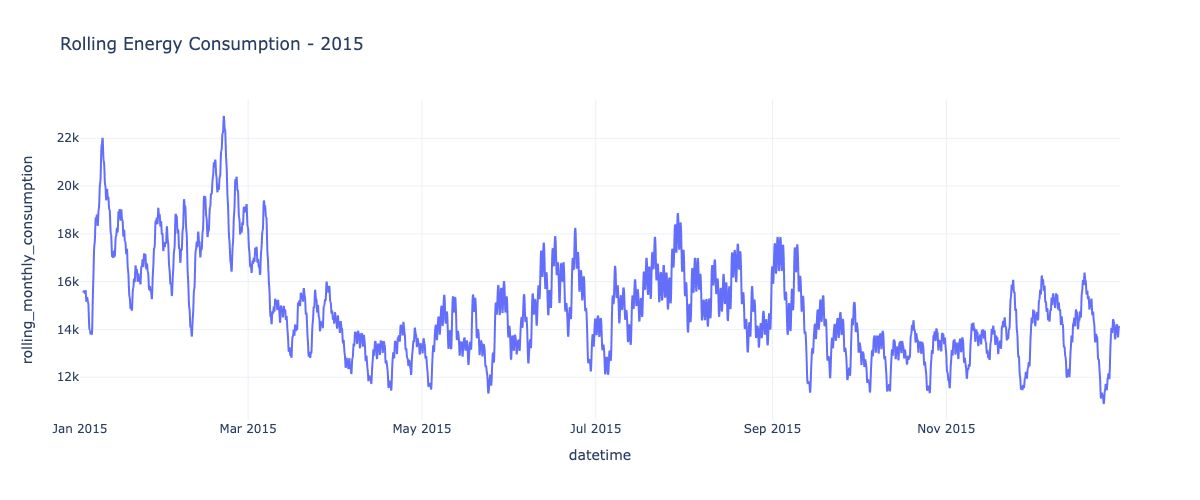
df_2015['rolling_monthly_consumption'] = df_2015['elec_cons'].rolling(window = 30).mean()
fig = px.line(df_2015,x = 'datetime' ,y = 'rolling_monthly_consumption', title = 'Rolling Energy Consumption - 2015')
fig.update_layout(
autosize=False,
width=1200,
height=500,
)
fig.show()
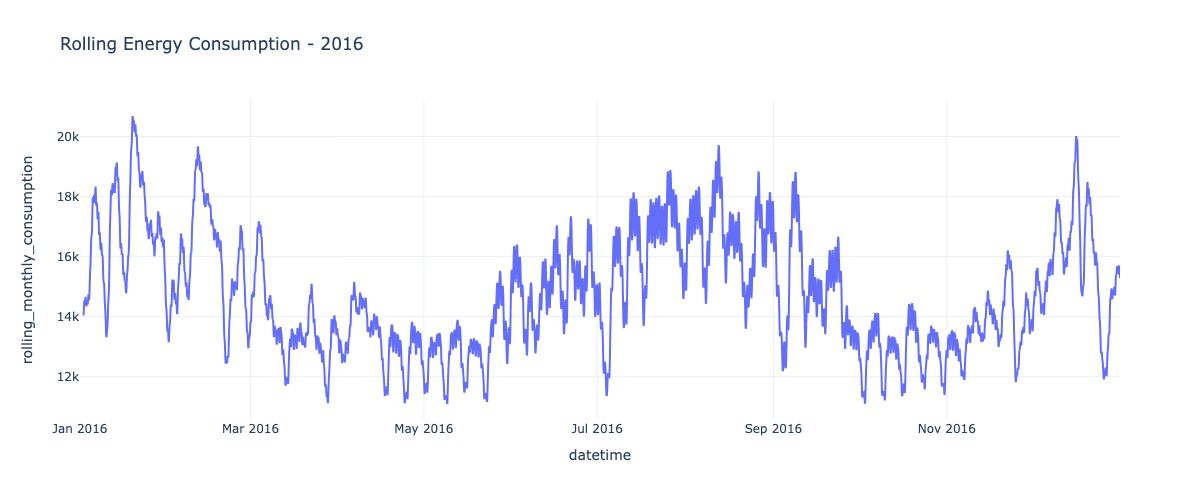
df_2016['rolling_monthly_consumption'] = df_2016['elec_cons'].rolling(window = 30).mean()
fig = px.line(df_2016,x = 'datetime' ,y = 'rolling_monthly_consumption', title = 'Rolling Energy Consumption - 2016')
fig.update_layout(
autosize=False,
width=1200,
height=500,
)
fig.show()
combined_df = df[df['year'].isin([2005,2008,2011])].groupby(['year','month_name'])['elec_cons'].mean().reset_index()
fig = px.line(combined_df, x = 'month_name', y = 'elec_cons', color = 'year', title = 'Seasonal Plot of Electricity Consumed')
fig.update_layout(
autosize=False,
width=1200,
height=500,
)
fig.show()
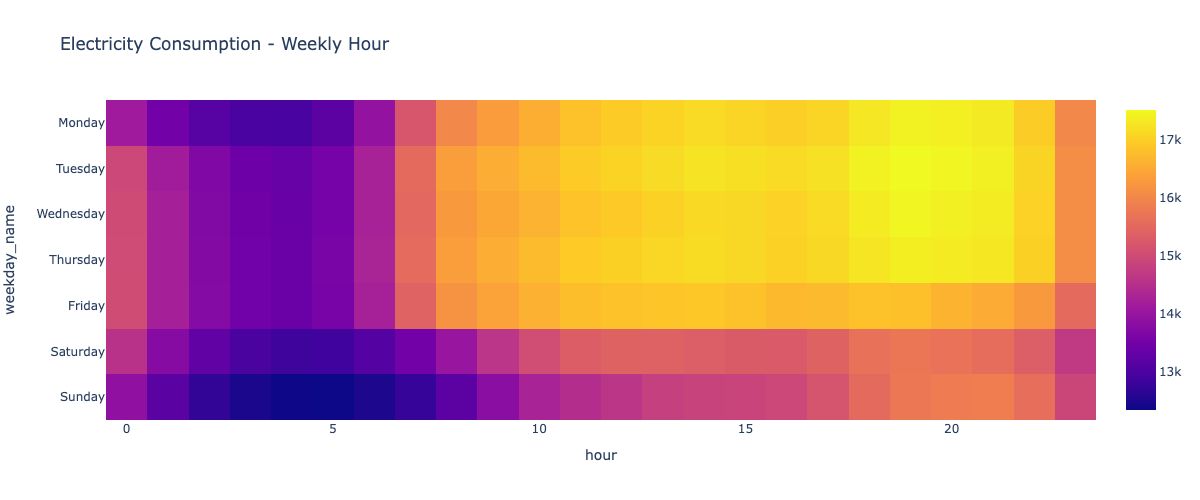
The following two visualizations offer an alternative format to observe the variation in hourly consumption across weekdays and the monthly consumption over the year. Heatmaps provide a valuable tool for understanding average trends and highlighting differences across various time periods.
plot_df = pd.pivot_table(df, index = 'weekday_name', values = 'elec_cons',columns = 'hour',aggfunc = 'mean')
fig = px.imshow(plot_df, height = 600, title = 'Electricity Consumption - Weekly Hour')
fig.update_layout(
autosize=False,
width=1200,
height=500,
)
fig.show()
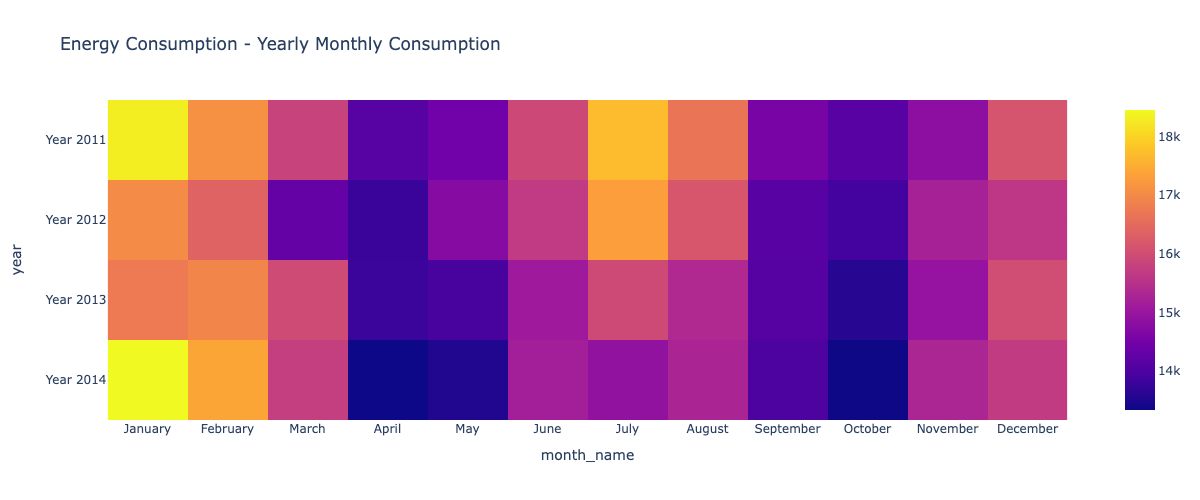
monthly_year = pd.pivot_table(df[df.year.isin([2011,2012, 2013, 2014])], index="year", values='elec_cons', columns="month_name", aggfunc="mean")
monthly_year.index = 'Year ' + monthly_year.index.astype(str)
fig = px.imshow(monthly_year, height = 600, title = 'Energy Consumption - Yearly Monthly Consumption' )
fig.update_layout(
autosize=False,
width=1200,
height=500,
)
fig.show()
Missing Value Treatment
Missing values are common in time-series data and must be handled appropriately. Several interpolation techniques exist, each with its strengths and limitations:
- Mean/Constant Fill: Replaces missing values with the mean/constant value. Simple but insensitive to local trends.
- Forward/Backward Fill: Propagates the previous/next known value. Preserves trends but introduces abrupt changes.
-
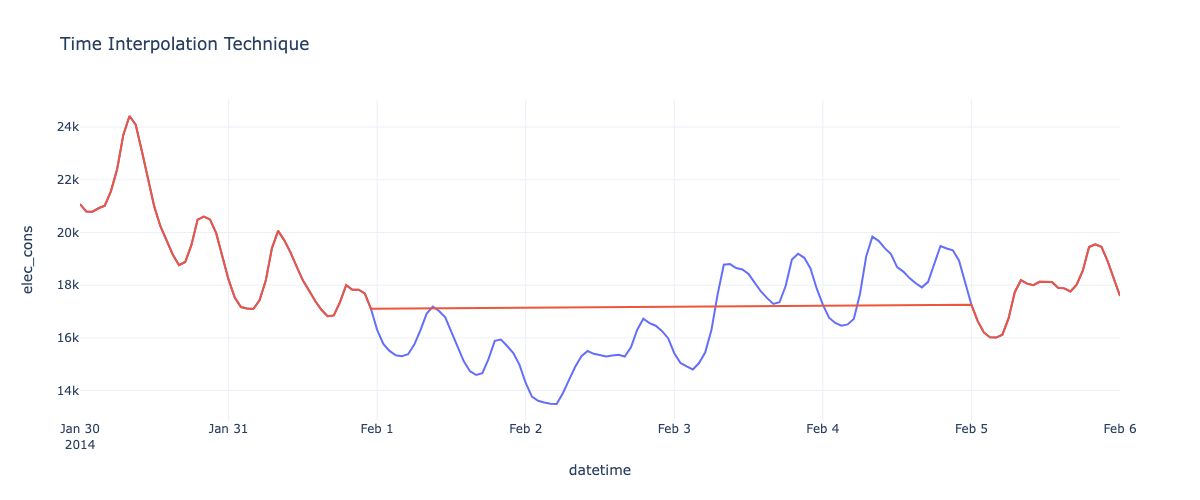
Time Interpolation: Fits a curve between known values surrounding the missing data. More adaptive to local trends.
The choice of technique depends on the amount of missing data, the sampling frequency, and the characteristics of the specific time-series. Performance metrics like mean absolute error (MAE) and mean absolute percentage error (MAPE) can help evaluate imputation accuracy.
missing_experiment = df.copy(deep = True)
missing_experiment['electricity_missing'] = missing_experiment['elec_cons']
missing_experiment = missing_experiment[missing_experiment['datetime'].dt.year.isin([2014])].reset_index(drop = True)
missing_experiment.set_index('datetime', inplace = True)
missing_window = slice('2014-02-01','2014-02-04')
missing_experiment.loc[missing_window,'electricity_missing'] = np.nan
vis_window = slice(pd.to_datetime(missing_window.start) - pd.Timedelta(days=2), pd.to_datetime(missing_window.stop) + pd.Timedelta(days=2))
In the code block above, we have taken a subsample from the existing large time series for the purpose of easy demonstration, and understanding. In here, we have introduced a missing time period as this data did not have any missing data originally.
We will in the missing data based on each of the above methodologies available at hand:
pd.options.plotting.backend = "plotly"
missing_experiment['mean_fill'] = missing_experiment['electricity_missing'].fillna(missing_experiment['electricity_missing'].mean())
missing_experiment['forward_fill'] = missing_experiment['electricity_missing'].ffill()
missing_experiment['backward_fill'] = missing_experiment['electricity_missing'].bfill()
missing_experiment['time_fill'] = missing_experiment['electricity_missing'].interpolate(method = 'time')
missing_experiment = missing_experiment[vis_window]
fig = px.line(missing_experiment, y = 'elec_cons', title = 'Time Interpolation Technique')
fig.add_scatter(x= missing_experiment.index, y = missing_experiment['time_fill'])
fig.update_layout(
autosize=False,
width=1200,
height=500,
showlegend = False
)
fig.show()
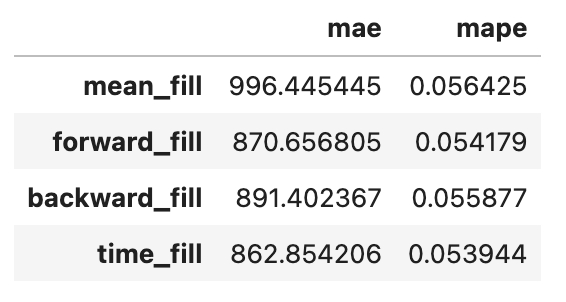
The question of which technique to use for your dataset is crucial, and the four techniques mentioned are just a few among many available options. To evaluate the effectiveness of any technique on your data, you can assess the Mean Absolute Percentage Error (MAPE) or Mean Absolute Error (MAE) on a subset of the non-missing data. This process helps determine the most suitable approach for handling missing data and allows you to replicate its efficacy accordingly.
error_dict = dict()
x = missing_experiment['elec_cons'].values
for imputed in ['mean_fill','forward_fill','backward_fill','time_fill']:
y = missing_experiment[imputed].values
local_error_dict = {
'mae': mean_absolute_error(x, y),
'mape':mean_absolute_percentage_error(x, y)
}
error_dict[imputed] = local_error_dict
pd.DataFrame(error_dict).T
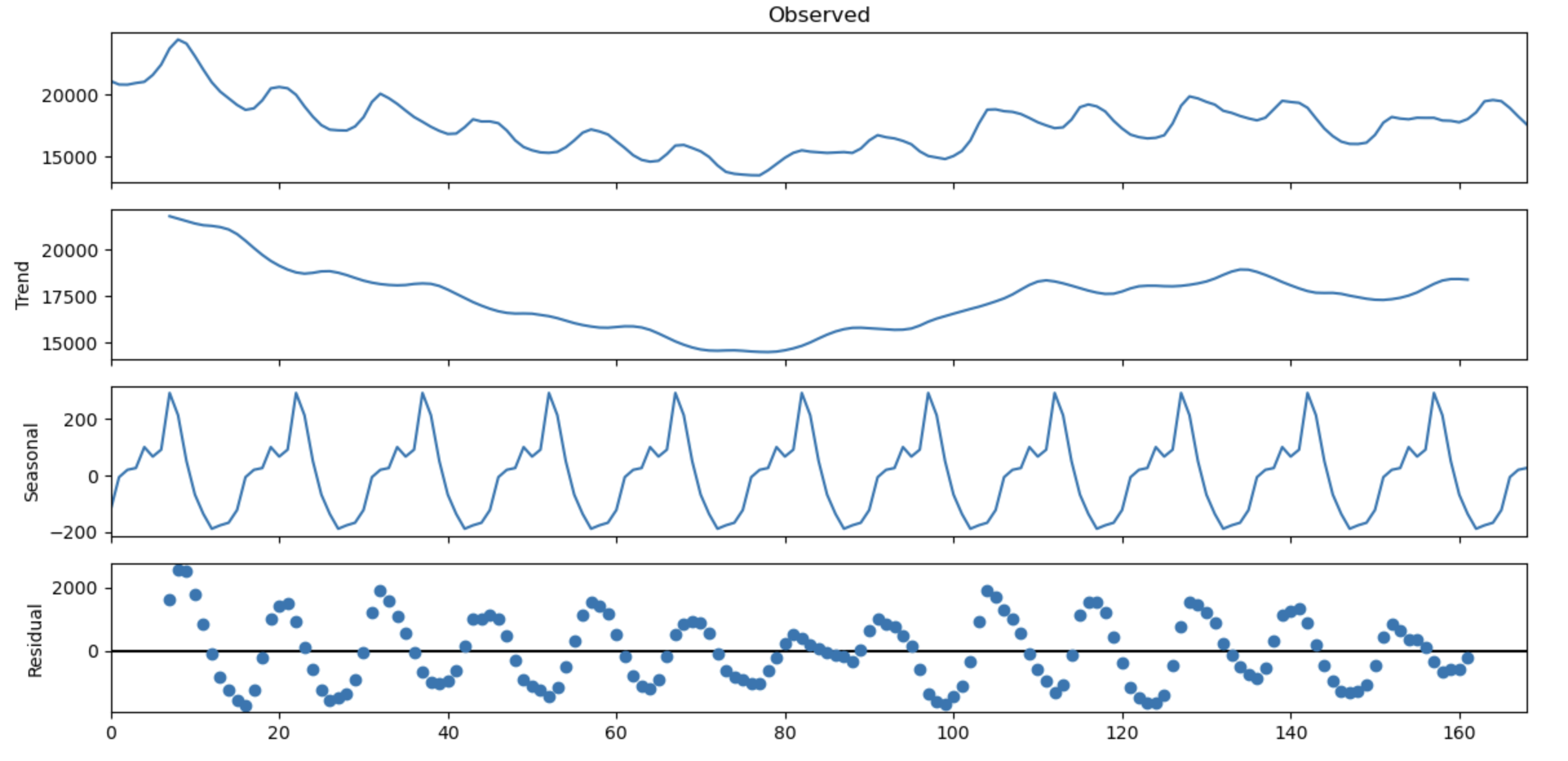
Time-Series Decomposition
To better understand the trend, seasonal, and residual components, we can decompose the time series via:
- Classical Seasonal Decomposition decomposes the series into seasonal, trend, and residual components additively or multiplicatively based on a defined period.
- STL (Seasonal-Trend Decomposition using LOESS) is a more flexible approach that extends classical decomposition using robust statistical techniques.
-
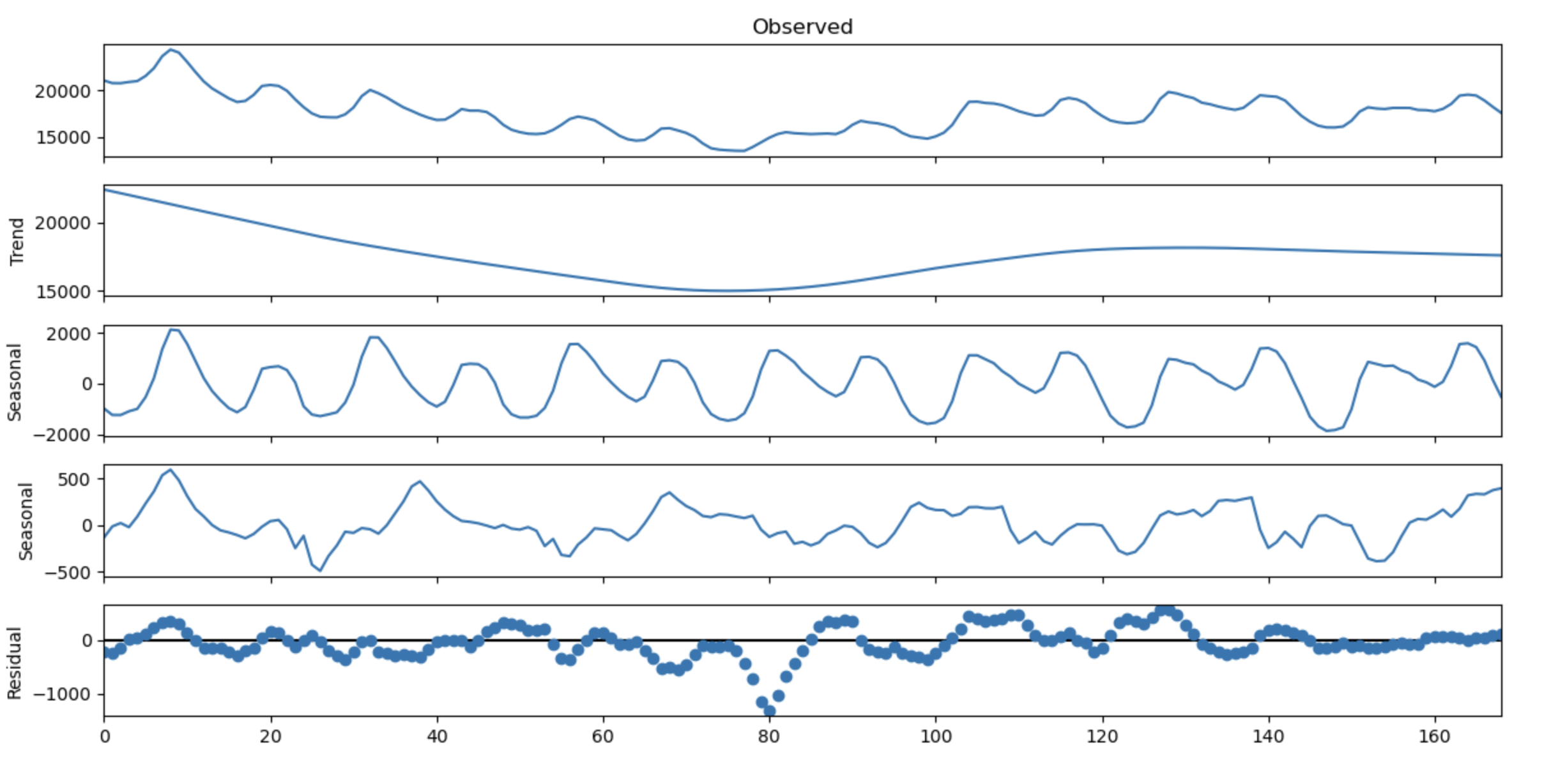
MSTL (Multiple Seasonal-Trend Decomposition using LOESS) can handle multiple seasonal periods, like daily and weekly cycles.
Visualizing these components can provide insights into the relative importance of each component and inform appropriate modeling strategies.
results = seasonal_decompose(
period = 15,
model = 'additive',
x = missing_experiment['elec_cons'].values
)
results.plot()
plt.show()
mstl_results = MSTL(
endog = missing_experiment['elec_cons'].values,
periods = (24, 30)
).fit()
mstl_results.plot()
plt.show()
Autocorrelation Analysis
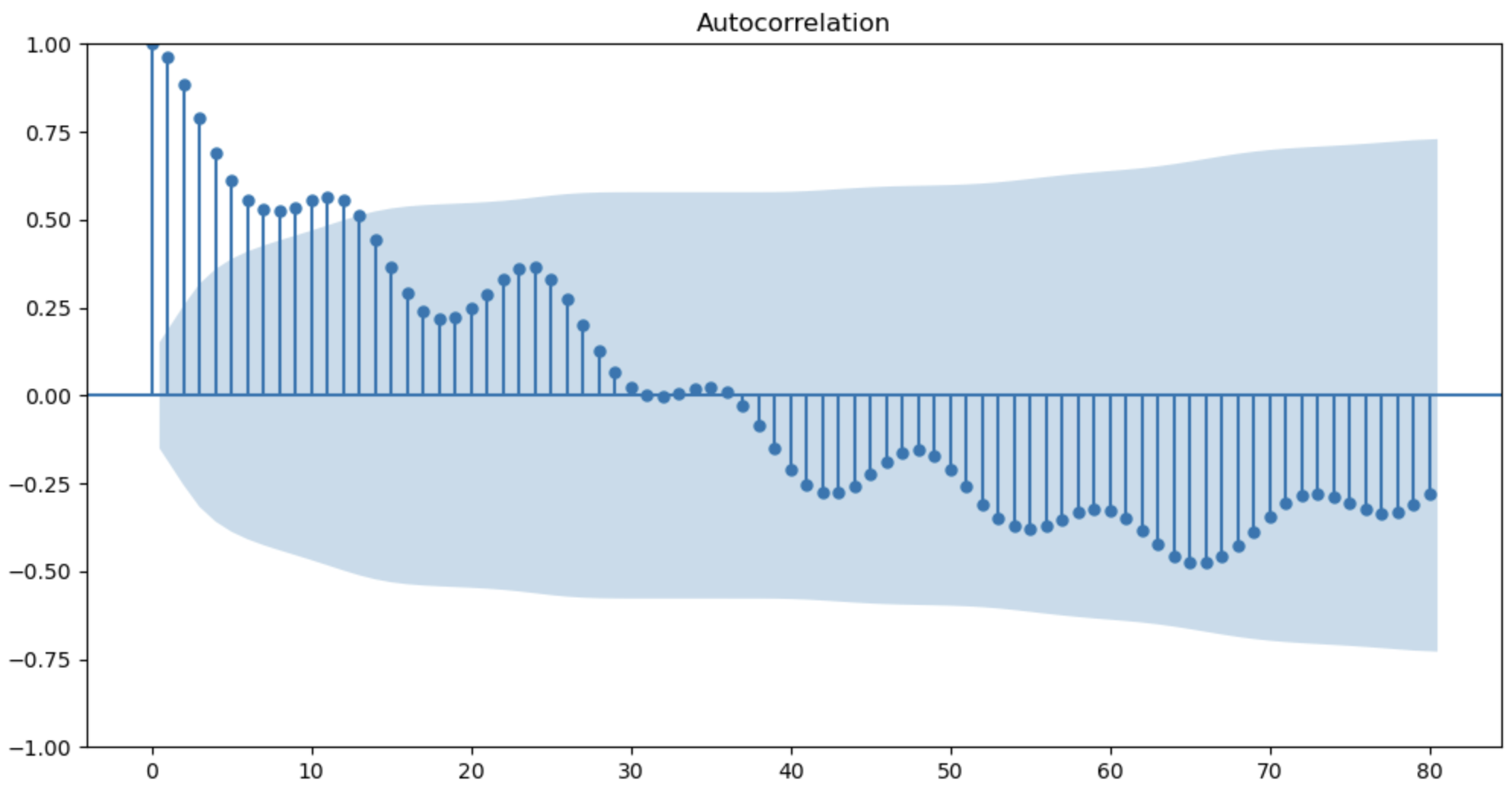
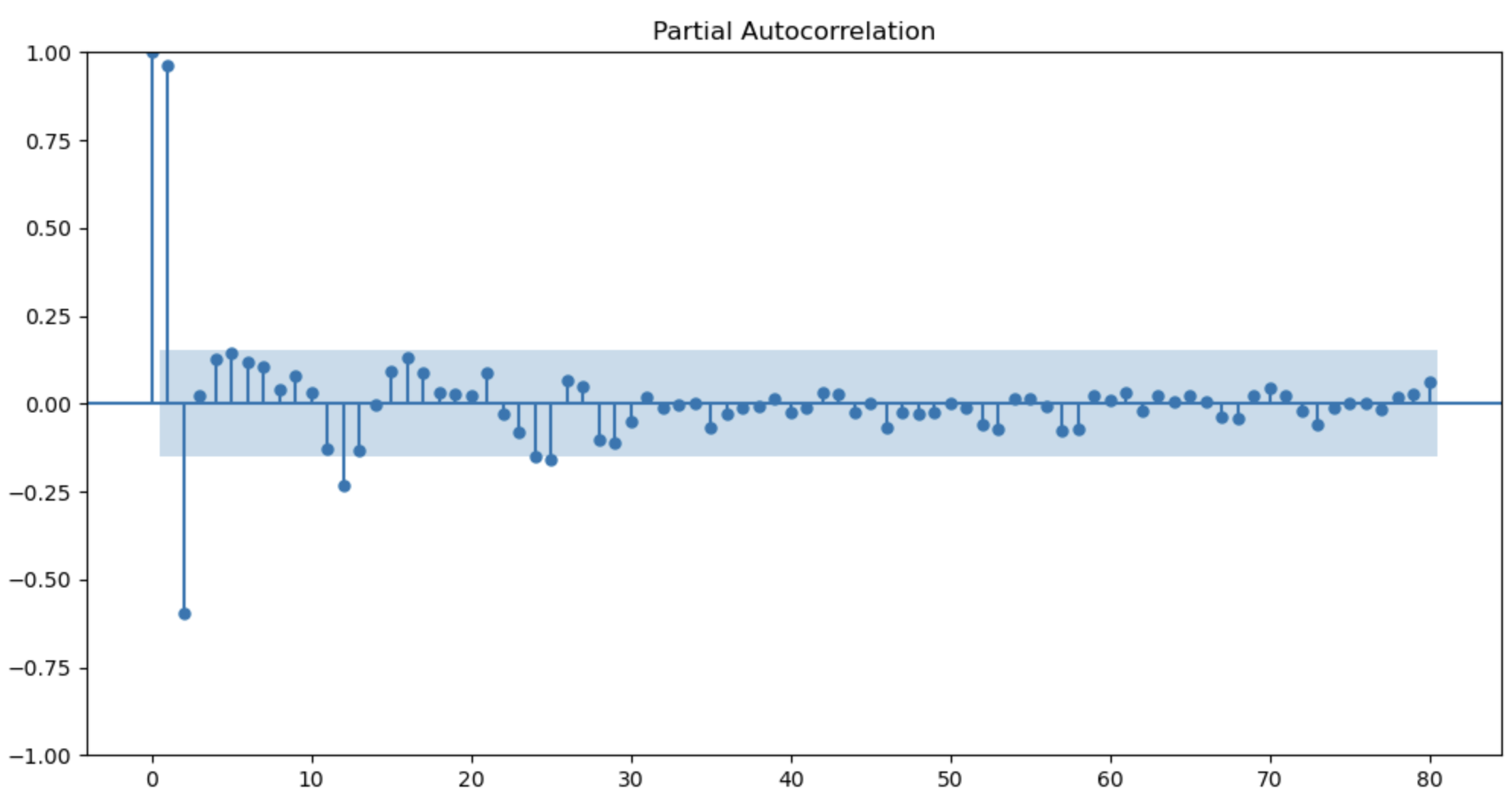
Autocorrelation measures the correlation between a time-series and its own lagged values. Plotting the autocorrelation function (ACF) and partial autocorrelation function (PACF) provides insights into:
- The number and type of autoregressive (AR) and moving average (MA) terms are needed for ARIMA modeling.
- Identifying seasonal patterns and periods, which inform seasonal ARIMA models.
- Detecting non-stationarity (slow decaying ACF) or over differencing (ACF cuts off abruptly).
Together, these ACF/PACF plots guide the appropriate orders and characteristics of ARIMA-family models.
# ACF Scores can be used to determine the dependence of each variable on the previous time value
acf_scores = acf(x=missing_experiment['elec_cons'].values, nlags=80)
pacf_scores = pacf(x=missing_experiment['elec_cons'].values, nlags=80)
plot_acf(missing_experiment['elec_cons'].values, lags=80)
plt.show()
plot_pacf(missing_experiment['elec_cons'].values, lags=80)
plt.show()
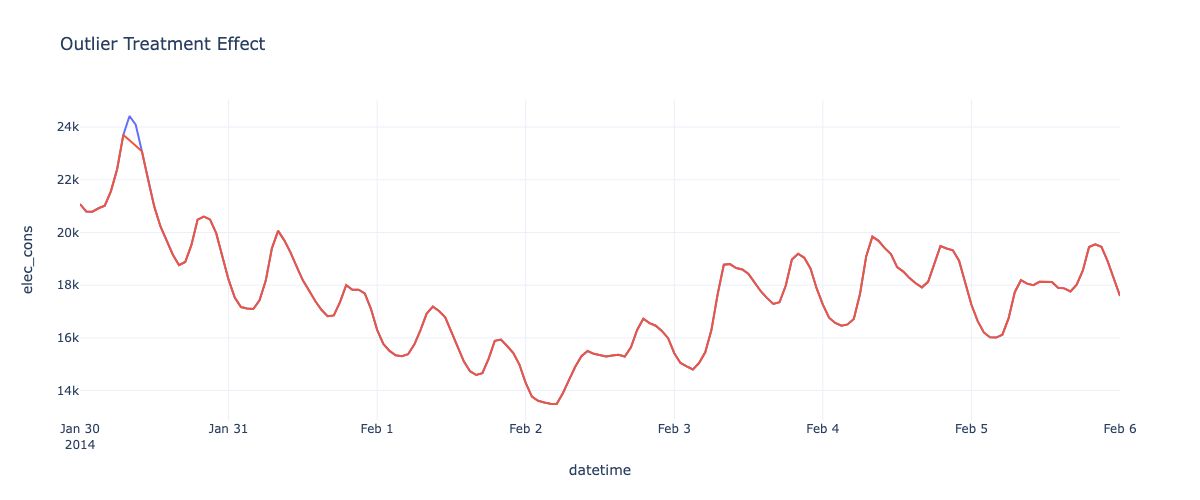
Outlier Detection and Treatment
Outliers can significantly impact time-series analysis and forecasting accuracy. Robust outlier detection methods like Isolation Forests can identify outlying observations while being resilient to masking and swamping effects.
Once detected, outliers can either be removed or adjusted using interpolation or other imputation techniques. The appropriate strategy depends on the nature and extent of outliers, as well as the downstream application (e.g., analysis vs forecasting).
x = missing_experiment['elec_cons'].values
estimator = IsolationForest(contamination = 0.01)
scaler = StandardScaler()
scaled_time_series = scaler.fit_transform(x.reshape(-1, 1))
pred = estimator.fit_predict(scaled_time_series)
pred = 1 - np.clip(pred, a_min=0, a_max=None)
missing_experiment['outliers'] = pred
missing_experiment['elec_cons_treated'] = np.where(missing_experiment['outliers']==0, missing_experiment['elec_cons'], np.nan)
missing_experiment['elec_cons_treated'] = missing_experiment['elec_cons_treated'].interpolate(mode = 'polynomial', degree = 2)
missing_experiment['outliers'].value_counts()
fig = px.line(missing_experiment, y = 'elec_cons', title = 'Outlier Treatment Effect')
fig.add_scatter(x= missing_experiment.index, y = missing_experiment['elec_cons_treated'])
fig.update_layout(
autosize=False,
width=1200,
height=500,
showlegend = False
)
fig.show()
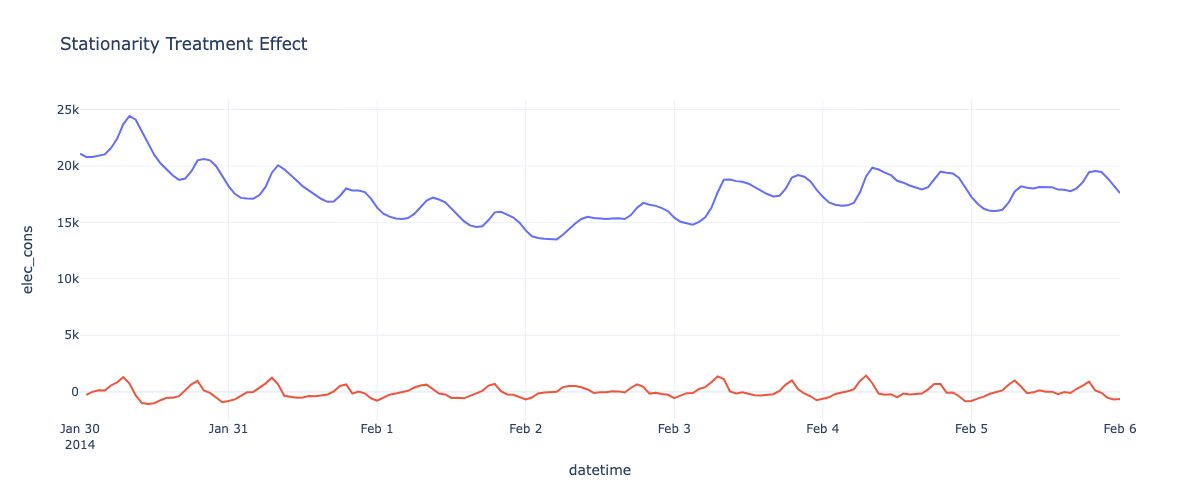
Stationarity and Differencing
Many time-series methods assume stationarity - that statistical properties like mean and variance are constant over time. If a series exhibits trends or seasonality, it is non-stationary and must be made stationary through differencing:
- First-order differencing computes the differences between consecutive observations to remove trends.
- Seasonal differencing removes seasonal effects by differencing values from the same season in previous periods.
Statistical tests like the Augmented Dickey-Fuller test can assess if a series is stationary and guide the appropriate order and type of differencing required.
ndiffs(x = missing_experiment['elec_cons'].values, test = 'adf')
missing_experiment['elec_cons_stationary'] = missing_experiment['elec_cons'].diff(1)
fig = px.line(missing_experiment, y = 'elec_cons', title = 'Outlier Treatment Effect')
fig.add_scatter(x= missing_experiment.index, y = missing_experiment['elec_cons_stationary'])
fig.update_layout(
autosize=False,
width=1200,
height=500,
showlegend = False
)
fig.show()
Conclusion
This article provided an overview of key concepts and techniques for understanding time-series data through an applied energy consumption example. We covered visualization, missing value treatment, decomposition into trend/seasonal/residual components, assessing stationarity, autocorrelation analysis, and outlier detection.
Mastering these fundamentals lays the groundwork for advanced time-series modeling and forecasting, which will be the focus of the next article in this series. By combining rigorous analysis with modern machine learning methods, we can unlock valuable insights and accurate predictions from time-series data across many domains.
References:
-
https://www.openforecast.org/adam/forecastingPlanningAnalytics.html
-
Modern Time Series Forecasting with Python: Explore industry-ready time series forecasting using modern machine learning and deep learning: 9781803246802: Joseph, Manu: Books. (n.d.).
-
(Deep Learning for Time Series Cookbook: Use PyTorch and Python Recipes for Forecasting, Classification, and Anomaly Detection: Cerqueira, Vitor, Roque, Luís: 9781805129233: Amazon.com: Books, n.d.)
-
(Forecasting: Principles and Practice: Hyndman, Rob J, Athanasopoulos, George: 9780987507136: Amazon.com: Books, n.d.)